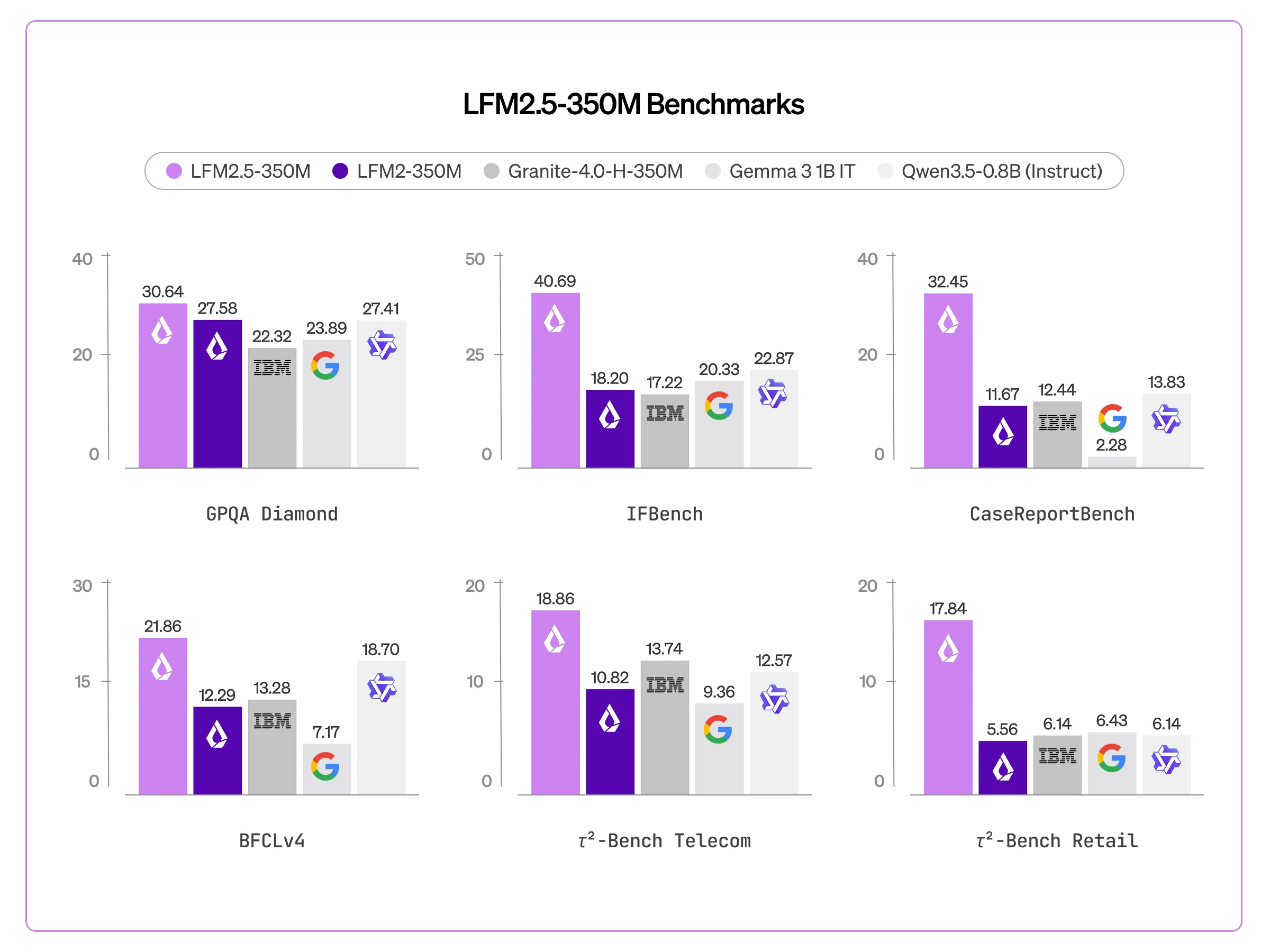
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...
Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liqu...

Energy bill support would be based on household income, Reeves says
The chancellor tells the BBC it is "too early" to say exactly who would get help but hinted any support would not arrive until the autumn.

Mitsubishi Goes Blockchain With JPMorgan For Payments Upgrade
Daily transaction volumes for JPMorgan’s blockchain-based payment system are approaching $10 billion as the bank expands its reach into the industrial ...

‘Harrowing’: Cyclone Narelle leaves graveyard of turtles, dolphins and seabirds in Western Australia
Exmouth local says devastating impact on wildlife along the coastline is ‘hard to put into words’Follow our Australia news live blog for latest updatesSign u...

XRP Is Quietly Leaving Binance. A Hidden Signal Says Something Is Building Beneath It
XRP is struggling to hold $1.35. The market is preparing for further downside. And beneath the price action, a quietly growing group of investors appears to ...

Chess in Pure SQL - DB Pro Blog
Comments
Chess in Pure SQL - DB Pro Blog
Comments
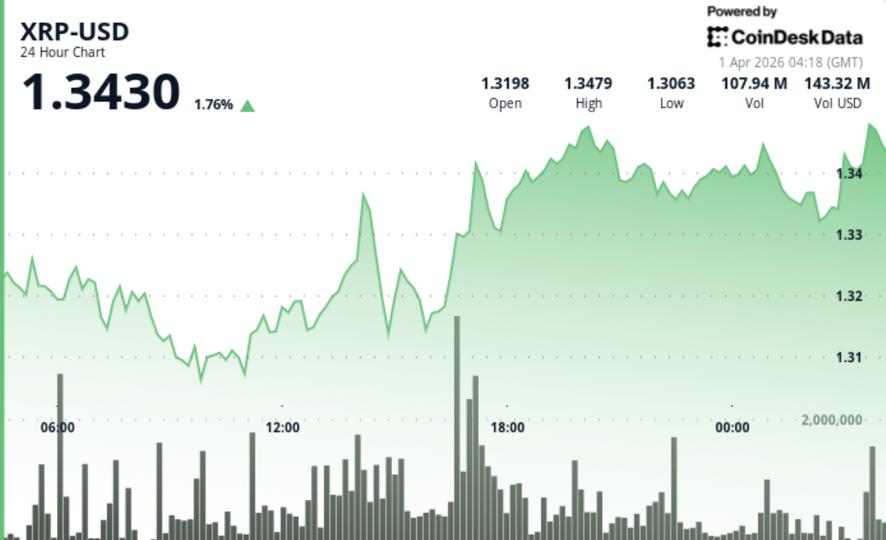
XRP price news: Ripple-linked token holds $1.34 as supply tightens
Record outflows and rising scarcity suggest accumulation, yet failure to break higher keeps setup unresolved.

My AI Team Has Four Models and One Human in the Loop
My AI Team Has Four Models and One Human in the Loop Last week, GPT found a security bug in code that Claude wrote. Not a hypothetical. Not a contrived test....

How DeFi Protocols Handle Security Upgrades in 2024
The tension sits at the heart of every DeFi protocol worth building: you need immutability to earn trust, but you need upgradability to survive. Smart contra...
How DeFi Protocols Handle Security Upgrades in 2024
The tension sits at the heart of every DeFi protocol worth building: you need immutability to earn trust, but you need upgradability to survive. Smart contra...
How DeFi Protocols Handle Security Upgrades in 2024
The tension sits at the heart of every DeFi protocol worth building: you need immutability to earn trust, but you need upgradability to survive. Smart contra...
How DeFi Protocols Handle Security Upgrades in 2024
The tension sits at the heart of every DeFi protocol worth building: you need immutability to earn trust, but you need upgradability to survive. Smart contra...
How DeFi Protocols Handle Security Upgrades in 2024
The tension sits at the heart of every DeFi protocol worth building: you need immutability to earn trust, but you need upgradability to survive. Smart contra...

What 10 Real AI Agent Disasters Taught Me About Autonomous Systems
Between October 2024 and February 2026, at least 10 documented incidents saw AI agents cause real damage — deleted databases, wiped drives, and even 15 years...
What 10 Real AI Agent Disasters Taught Me About Autonomous Systems
Between October 2024 and February 2026, at least 10 documented incidents saw AI agents cause real damage — deleted databases, wiped drives, and even 15 years...

I built Newsroulette: the anti-feed for tech news
I was tired of algorithmic feeds. Built newsroulette.ai — one random curated article per page load about AI, quantum, chips, markets, self-driving cars, or f...
I built Newsroulette: the anti-feed for tech news
I was tired of algorithmic feeds. Built newsroulette.ai — one random curated article per page load about AI, quantum, chips, markets, self-driving cars, or f...

Understanding Object-Oriented Programming (OOP) Concepts
Object-Oriented Programming (OOP) is one of the most widely used programming paradigms in modern software development. It helps developers design application...
Understanding Object-Oriented Programming (OOP) Concepts
Object-Oriented Programming (OOP) is one of the most widely used programming paradigms in modern software development. It helps developers design application...
Tietosuojavalintasi